Shared Memory Concurrency Roadmap
过去很多年, 单核处理器性能基本沿摩尔定律的预测不断提速. 然而, 设计上越来越复杂, 也越来越接近物理极限, 引起了生产成本和功耗的增大, 性价比降低. 2005年前后, CPU制造商, 开始从原来提升单核处理器的ILP(instruction-level parallelism), 转向在单个芯片上增加核数, 挖掘multicore processor的性能[1].
目前, 市面上, 商用廉价或高端服务器, 一般都采用shared memory multicore multiprocessor. 高端服务器有几十~几百core, 几百GB甚至上TB的内存. 例如: Intel® Xeon® Processor E7-8894 v4支持8 socket * 24 core, 3.07TB内存[2]. 服务器提供了强大处理的能力, 可将系统dataset(比如in-memory database)可以全驻于内存, 采用multi-threaded编程, 共享地址空间, 提升计算性能[3][4].
shared memory concurrency涉及三个方面: parallelism, performance和correctnesss.
More...
对频繁确认 (ACK) 的依赖是当前传输协议设计的产物,而不是基本要求。本文分析了WLAN中数据包和ACK在无线介质上的争用和冲突引起的问题,提出了一种ACK机制,可以最小化QUIC中ACK帧的强度,提高传输层连接的性能。
More...
本文档指定了在 QUIC 中封装 RTP 和 RTCP 数据包的最小映射。它还讨论了如何利用端点中 QUIC 实现的状态来减少 RTCP 数据包的交换。
More...
本文翻译自 Google 2017 的论文:
Cardwell N, Cheng Y, Gunn CS, Yeganeh SH, Jacobson V. BBR: congestion-based congestion control. Communications of the ACM. 2017 Jan 23;60(2):58-66.
论文副标题:Measuring Bottleneck Bandwidth and Round-trip propagation time(测量瓶颈带宽和往返传输时间)。
BBR 之前,主流的 TCP 拥塞控制算法都是基于丢包(loss-based)设计的, 这一假设最早可追溯到上世纪八九十年代,那时的链路带宽和内存容量分别以 Mbps 和 KB 计,链路质量(以今天的标准来说)也很差。
三十年多后,这两个物理容量都已经增长了至少六个数量级,链路质量也不可同日而语。特别地,在现代基础设施中, 丢包和延迟不一定表示网络发生了拥塞,因此原来的假设已经不再成立。 Google 的网络团队从这一根本问题出发,(在前人工作的基础上) 设计并实现了一个基于拥塞本身而非基于丢包或延迟的拥塞控制新算法,缩写为 BBR。
简单来说,BBR 通过应答包(ACK)中的 RTT 信息和已发送字节数来计算 真实传输速率(delivery rate),然后根据后者来调节客户端接下来的 发送速率(sending rate),通过保持合理的 inflight 数据量来使 传输带宽最大、传输延迟最低。另外,它完全运行在发送端,无需协议、 接收端或网络的改动,因此落地相对容易。
Google 的全球广域网(B4)在 2016 年就已经将全部 TCP 流量从 CUBIC 切换到 BBR, 吞吐提升了 2~25 倍;在做了一些配置调优之后,甚至进一步提升到了 133 倍(文中有详细介绍)。
More...
互联网曾广泛使用基于丢包的拥塞控制算法,例如Reno([Jac88], [Jac90], [WS95] [RFC5681])和 CUBIC(HRX08, draft-ietf-tcpm-cubic),这类算法认为丢包和拥塞是等效的。长久以来这类算法都运作的很好,但这并不能说明他们是绝对正确的。这种良好的表现是由于网络交换机和路由器的缓冲区都十分适配当时的网络带宽。而一旦发送者的发送速率足够快,缓冲区便会被快速填满,进而引发丢包。
实际上丢包并不等效于拥塞。拥塞可以被看作是一种在网络路径中,传输中的数据量始终大于带宽-时延积的场景。随着互联网的不断发展,丢包现象在非拥塞场景下也频繁发生。而基于丢包的拥塞控制策略给网络带来了源源不断的问题:
- 浅缓存:在浅缓存场景下,丢包往往发生在拥塞之前。高速、长距离的现代网络,搭配上消费级的浅缓存交换机,基于丢包的拥塞控制算法可能会导致极其糟糕的吞吐量,而这种现象则归咎于这类算法对于丢包的过激反应。流量突发引起的丢包会使发送速率乘性递减(这种丢包现象在空闲网络中也会频繁发生)。这种动态特性,使得基于丢包的拥塞控制算法在实际应用中很难对网络带宽进行充分利用:维持10Gbps/100ms RTT的网络,必须要求其丢包率在0.000003%以下。而更为实际的1%的丢包率,则会导致其只能维持在3Mbps/100ms(无论是瓶颈带宽的性能如何)。
- 深缓存:在有着深缓存的瓶颈链路中,拥塞往往发送在丢包之前。在现今的的边缘网络中,基于丢包的拥塞控制算法对众多最后几英里的设备,进行了深缓存的反复填充,引发了不必要的数秒级的排队延时,也就是“缓冲膨胀”的问题。
BBR拥塞控制算法使用了另类的方式:不用丢包去衡量拥塞是否发生,而是直接对网络建模来避免以及应对真实的拥塞。
BBR算法已经在之前的论文中大致描述过 [CCGHJ16] [CCGHJ17],活跃性的社区工作也在持续进行中。该文档将对现有的BBR算法进行详细解释。
该文档将以下列形式进行组织:第二节将会给出多种术语定义。第三节是对BBR算法的设计概述。第四节将对BBR算法进行细节分析,包括BBR的网络路径模型,控制参数以及状态机。
More...
1.概述
2.congestion_controller模块
2.1 congestion_controller模块组成
2.2 远端带宽探测
2.3 loss_based_bandwidth_estimation基于丢包的带宽评估
2.4 delay_based_bwe基于延迟的带宽评估
2.5 receive_side_congestion_controller接收端拥塞控制
3.remote_bitrate_estimator模块
4.pacing模块
More...
自 2015 年以来,QUIC 协议开始在 IETF 进行标准化并被国内外各大厂商相继落地。鉴于 QUIC 具备“0RTT 建联”、“支持连接迁移”等诸多优势,并将成为下一代互联网协议:HTTP3.0 的底层传输协议,蚂蚁集团支付宝客户端团队与接入网关团队于 2018 年下半年开始在移动支付、海外加速等场景落地 QUIC。
本文是综述篇,介绍 QUIC 在蚂蚁的整体落地情况。之所以是综述,是因为 QUIC 协议过于复杂,如果对标已有的协议,QUIC 近似等于 HTTP + TLS +TCP,无法详细的毕其功于一役,因此我们通过综述的方式将落地的重点呈现给读者,主要介绍如下几个部分:
-
QUIC背景:简单全面的介绍下 QUIC 相关的背景知识
-
方案选型设计:详细介绍蚂蚁的落地方案如何另辟蹊径、优雅的支撑 QUIC 的诸多特性,包括连接迁移等
-
落地场景:介绍 QUIC 在蚂蚁的两个落地场景,包括:支付宝客户端链路以及海外加速链路
-
几项关键技术:介绍落地 QUIC 过程中核心需要解决的问题,以及我们使用的方案,包括:“支持连接迁移”、“提升 0RTT 比例", "支持 UDP 无损升级”以及“客户端智能选路” 等
-
几项关键的技术专利
More...
为什么越来越多的团队投入QUIC协议自研实现?来自阿里巴巴淘系技术的刘彦梅的投稿很好的解释了背后的原因——提供更好的灵活性。同时,遵守标准的IETF QUIC也让研发投入能产生长期回报。刘彦梅介绍了XQUIC的前生今世,以及未来的开源计划。为什么越来越多的团队投入QUIC协议自研实现?来自阿里巴巴淘系技术的刘彦梅的投稿很好的解释了背后的原因——提供更好的灵活性。同时,遵守标准的IETF QUIC也让研发投入能产生长期回报。刘彦梅介绍了XQUIC的前生今世,以及未来的开源计划。为什么越来越多的团队投入QUIC协议自研实现?来自阿里巴巴淘系技术的刘彦梅的投稿很好的解释了背后的原因——提供更好的灵活性。同时,遵守标准的IETF QUIC也让研发投入能产生长期回报。刘彦梅介绍了XQUIC的前生今世,以及未来的开源计划。
为什么越来越多的团队投入QUIC协议自研实现?来自阿里巴巴淘系技术的刘彦梅的投稿很好的解释了背后的原因——提供更好的灵活性。同时,遵守标准的IETF QUIC也让研发投入能产生长期回报。刘彦梅介绍了XQUIC的前生今世,以及未来的开源计划。
XQUIC是阿里巴巴淘系架构团队自研的IETF QUIC标准化协议库实现,在手机淘宝上进行了广泛的应用,并在多个不同类型的业务场景下取得明显的效果提升,为手机淘宝APP的用户带来丝般顺滑的网络体验:
从以上提升效果可以看出,对QUIC的一个常见认知谬误:“QUIC只对弱网场景有优化提升”是不准确的。实际上QUIC对于整体网络体验有普遍提升,弱网场景由于基线较低、提升空间更显著。此外,在5G推广初期,基站部署不够密集的情况下,如何保证稳定有效带宽速率,是未来2-3年内手机视频应用将面临的重大挑战,而我们研发的MPQUIC将为这些挑战提供有效的解决方案。
本文将会重点介绍XQUIC的设计原理,面向业务场景的网络传输优化,以及面向5G的Multipath QUIC技术(多路径QUIC)。
More...
腾讯核心业务用户登录耗时降低30%,下载场景500ms内请求成功率从HTTPS的60%提升到90%,腾讯的移动端APP在弱网、跨网场景下取得媲美正常网络的用户体验。这是腾讯网关sTGW团队打造的TQUIC网络协议栈在实时通信、音视频、在线游戏、在线广告等多个腾讯业务落地取得的成果。
TQUIC基于下一代互联网传输协议HTTP3/QUIC深度优化,日均请求量级突破千亿次,在腾讯云CLB、CDN开放云客户使用。本文重点分享了sTGW团队在协议栈基础能力、私有协议、明文传输等功能研发经验,并且针对弱网场景,分享腾讯如何基于0-RTT握手、连接迁移、实时传输等能力帮助业务用户体验提升。
More...
到现在,我已经做了超过 21 年开发,可以说,我生命中超过一半的时间都在编程,那既是我的职业,也成了我的习惯。
下面是我在开发过程中学到的 10 条最有价值的经验。
1 你永远不可能什么都知道
尤其是在开始的时候,我以为我什么都能学会,在开发生涯的大部分时间里,我都是这样想的。但是,每次我学了什么新东西,就打开了一个全新的世界,里面有不同的概念和技术。
那似乎很有吸引力,你很愿意尝试,希望把什么都学会,但这是一个没有终点的旅程。如果要学的话,总是有其他的库、框架以及其他很酷的东西可以学。
因为似乎永远无法达成自己的目标,所以最终你的热情会慢慢冷却。最好是立足于你最擅长的东西,然后因需而学,即在真正需要的时候才学习新东西。这可以让你保持清醒,维持学习的动力。
你还可以把这一点应用在任何其他的领域。不是什么都知道才能达成预期的结果。利用这一点来打造自己的优势,在需要的时候学习。
More...
大家好,我是Will Law,目前在旧金山的Akamai Technologies办公室工作。我生活和工作的地方距离金门大桥非常近,也就是图片上的地方。能与美国和中国的工程师交流一直是我的荣幸,尤其是讨论在全球范围内具有重要意义的下一代Web协议问题。而我今天要介绍的主题就是关于WebTransport(网络传输)。

话不多说,让我们开始吧。我们首先要考虑下为什么需要一个新的协议?为什么HTTP1、HTTP2、HTTP3或WebSocket协议不能满足我们的需求?我将介绍当前这些协议存在的问题,并引出什么是WebTransport;它包括哪些部分;以及什么是网络堆栈;此外,我还会介绍W3C(国际网络联盟)提出的Web浏览器应用程序接口草案。最后,我们还将讨论如何参与该协议的开发。
在开始之前,我想先感谢Jeff Posnick、Victor Vasilief、Peter Thatcher、Yutaka Hirano和Bernard Aboba为本次演示提供的数据和内容素材。他们一直是WebTransport发展中不可或缺的一部分,尤其是在社区草案形成过程中做出了很多贡献,因此我想对他们提供的信息表示感谢。

More...
QUIC(Quick UDP Internet Connections),即快速UDP网络连接,是被设计用在传输层的网络协议,最初由Google的Jim Roskind提出,最初实现和部署在2012年,截止目前仍然是一个因特网草案,但已经被广泛应用于Google浏览器和Google服务器之间。目前Chorme、Microsoft Edge、Firefox、Safari均已经支持QUIC,尽管不常用。
QUIC增加了面向连接的TCP网络应用程序的性能,它通过使用UDP在两个端点之间建立一系列多路复用(multiplexing)的连接实现这个目的,它同时被用来代替(obsolesce)TCP在网络层的作用,因此也被戏称为TCP/2
QUIC与HTTP/2的多路复用连接紧密结合,允许多个数据流独立的到达终端,因此一个数据包与其他的数据流传输的数据包丢失无关。与之相对的是,TCP如果有任何数据包的丢失或延迟,就会发生队头阻塞
QUIC的另一个目标是减少连接和传输时候的延迟,以及评估每一个方向的带宽来避免阻塞。它还将拥塞控制算法移动到两个端点的用户空间,而不是内核空间,根据QUIC的实现,这将会提升算法的性能。此外,当遇到预期的错误的时候,QUIC协议可以使用前向纠错(forward error correction)FEC来提升性能。2018年10月,IETF的HTTP和QUIC工作组共同决定将QUIC上的HTTP映射称为HTTP/3,以使其在全球范围内标准化。
More...
QUIC 是什么?
简单来说,QUIC (Quick UDP Internet Connections) 是一种基于 UDP 封装的安全 可靠传输协议,他的目标是取代 TCP 并自包含 TLS 成为标准的安全传输协议。下图是 QUIC 在协议栈中的位置,基于 QUIC 承载的 HTTP 协议进一步被标准化为 HTTP3.0。
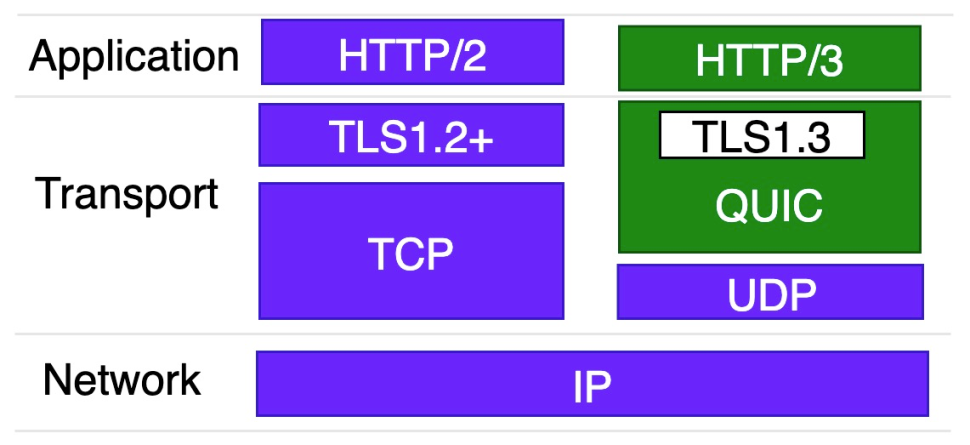
More...
一、特征提取Feature Extraction:
二、图像分割Image Segmentation:
三、目标检测Object Detection:
四、显著性检测Saliency Detection:
五、图像分类、聚类Image Classification, Clustering
五、图像分类、聚类Image Classification, Clustering
六、抠图Image Matting
七、目标跟踪Object Tracking:
八、Kinect:
九、3D相关:
十、机器学习算法:
十一、目标、行为识别Object, Action Recognition:
十一、目标、行为识别Object, Action Recognition:
十二、图像处理:
十三、一些实用工具:
十四、人手及指尖检测与识别:
十五、场景解释:
十六、光流Optical flow:
十七、图像检索Image Retrieval:
十八、马尔科夫随机场Markov Random Fields:
十九、运动检测Motion detection:
More...
rd_kafka 的常见发布和订阅配置选项的整理。这些选项可以用于设置 Kafka 生产者(发布者)和消费者(订阅者)的行为和属性。
发布者配置选项:
-
bootstrap.servers:Kafka 集群的地址列表,用于引导连接。
示例代码:
rd_kafka_conf_set(conf, "bootstrap.servers", "localhost:9092", errstr, sizeof(errstr));
More...
常用快捷键
编辑器与窗口管理
代码编辑
格式调整
光标相关
重构代码
查找替换
显示相关
其他
修改默认快捷键
More...
下面说一下猫盘刷了群晖之后怎么安装常用的下载软件吧,这个方法除了猫盘以外,应该也可以在其他ARM版群晖上使用。ARM版群晖是没法安装docker的,一般安装软件是依靠群晖的套件中心。
安装transmission的话比较简单,直接在套件中心添加第三方源(http://packages.synocommunity.com),然后就可以直接在套件中心的社群里面找到transmission套件进行安装就可以了。
相比起transmission,个人更喜欢qBittorrent,qBittorrent可以通过修改种子的分类管理下载文件的保存路径,比较方便整理。但是群晖的套件中心中没有qBittorrent,也没有aira2,那应该怎么安装呢?
研究了一下,发现其实ARM版群晖是可以安装entware的,那就可以通过opkg来安装entware软件仓库中的大量软件了,可玩性大增有没有!
More...
在使用JRTPLIB的发送数据的时候需要设置时间戳单位(timestamp)和时间戳增量(timestamp increment)。
看了网上一些文章,细细想来现在才想通这个问题。
More...
简介
Address Sanitizer(ASan)是一个快速的内存错误检测工具。它非常快,只拖慢程序两倍左右(比起Valgrind快多了)。
它包括一个编译器instrumentation模块和一个提供malloc()/free()替代项的运行时库。
从gcc 4.8开始,AddressSanitizer成为gcc的一部分。当然,要获得更好的体验,
最好使用4.9及以上版本,因为gcc 4.8的AddressSanitizer还不完善,最大的缺点是没有符号信息。
More...
最近在项目中用到了google的heap profiler工具来分析内存占用,效果非常显著,因此在这里写一篇博客记录一下使用过程中遇到的一些问题。
heap profiler依赖于tcmalloc,所以先要在本机安装tcmalloc,安装过程非常的简单。然后开始使用tcmalloc进行编译自己写的程序。
先写一段申请大量内存的代码:
More...
C/C++等底层语言在提供强大功能及性能的同时,其灵活的内存访问也带来了各种纠结的问题。如果crash的地方正是内存使用错误的地方,说明你人品好。如果crash的地方内存明显不是consistent的,或者内存管理信息都已被破坏,并且还是随机出现的,那就比较麻烦了。当然,祼看code打log是一个办法,但其效率不是太高,尤其是在运行成本高或重现概率低的情况下。另外,静态检查也是一类方法,有很多工具(lint, cppcheck, klockwork, splint, o, etc.)。但缺点是误报很多,不适合针对性问题。另外好点的一般还要钱。最后,就是动态检查工具。下面介绍几个Linux平台下主要的运行时内存检查工具。绝大多数都是开源免费且支持x86和ARM平台的。
- 首先,比较常见的内存问题有下面几种:
• memory overrun:写内存越界
• double free:同一块内存释放两次
• use after free:内存释放后使用
• wild free:释放内存的参数为非法值
• access uninitialized memory:访问未初始化内存
• read invalid memory:读取非法内存,本质上也属于内存越界
• memory leak:内存泄露
• use after return:caller访问一个指针,该指针指向callee的栈内内存
• stack overflow:栈溢出
More...
QUIC 传输协议具有 HTTP 传输所需的几个特性,例如流多路复用、每个流的流控制和低延迟连接建立。本文档描述了 HTTP 语义在 QUIC 上的映射。本文档还确定了 QUIC 包含的 HTTP/2 功能,并描述了如何将 HTTP/2 扩展移植到 HTTP/3。
More...
在Linux上做网络应用的性能优化时,一般都会对TCP相关的内核参数进行调节,特别是和缓冲、队列有关的参数。网上搜到的文章会告诉你需要修改哪些参数,但我们经常是知其然而不知其所以然,每次照抄过来后,可能很快就忘记或混淆了它们的含义。本文尝试总结TCP队列缓冲相关的内核参数,从协议栈的角度梳理它们,希望可以更容易的理解和记忆。注意,本文内容均来源于参考文档,没有去读相关的内核源码做验证,不能保证内容严谨正确。作为Java程序员没读过内核源码是硬伤。
下面我以server端为视角,从 连接建立、 数据包接收 和 数据包发送 这3条路径对参数进行归类梳理。
一、连接建立
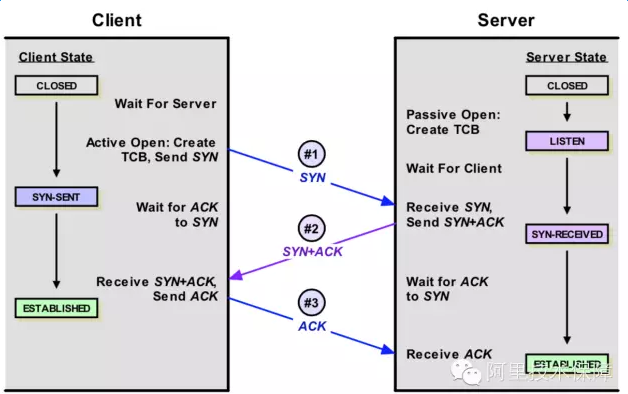
More...
关于开源图书有热心的伙伴和网友在网络上做了大量整理,本文为大家刊载免费编程类中文开源电子书合集全集,转载自 LinuxStory
暂无同学编辑和校对的文章 https://linuxstory.org/free-chinese-programming-books/,(原始 GitHub 地址:https://github.com/justjavac/free-programming-books-zh_CN)转载的原因是未来开源工场的小伙伴会就这个 repo 和话题做更加细致的整理,包括技术类、非技术类等等,希望帮到更多的小伙伴。如果你有兴趣一起做这件事情,请考虑联系工场电报群管理员或者 QQ 群群主。
书山有路勤为径,学海无涯苦作舟!
开源不仅局限于软件领域,开源同样意味着自由选择的权利和对知识开放的追求
More...

