Shared Memory Concurrency Roadmap
过去很多年, 单核处理器性能基本沿摩尔定律的预测不断提速. 然而, 设计上越来越复杂, 也越来越接近物理极限, 引起了生产成本和功耗的增大, 性价比降低. 2005年前后, CPU制造商, 开始从原来提升单核处理器的ILP(instruction-level parallelism), 转向在单个芯片上增加核数, 挖掘multicore processor的性能[1].
目前, 市面上, 商用廉价或高端服务器, 一般都采用shared memory multicore multiprocessor. 高端服务器有几十~几百core, 几百GB甚至上TB的内存. 例如: Intel® Xeon® Processor E7-8894 v4支持8 socket * 24 core, 3.07TB内存[2]. 服务器提供了强大处理的能力, 可将系统dataset(比如in-memory database)可以全驻于内存, 采用multi-threaded编程, 共享地址空间, 提升计算性能[3][4].
shared memory concurrency涉及三个方面: parallelism, performance和correctnesss.
并行(Parallelism)
并行可加速计算. 通常采用两种方式[5]:
- partitioning: 将数据分割为若干由不同worker管理的partition, 可并行处理不同的partition.
- pipelining: 将任务分为若干彼此衔接的stage, 构成pipeline; stage之间通过共享存储或消息传递的方式传递中间结果. 多个任务不同stage可活跃于pipeline的不同stage, 获得inter-stage parallelism; 每个stage的输入数据或者消息分成若干partition, 由一组计算节点处理, 可获得intra-stage parallelism.
partitioning和pipelining都可以采用共享存储的方式, 对数据分而治之, 利用计算节点和数据之间的亲俯性(affinity), 提升计算性能.
例子比比皆是, 如:
- MapReduce[6]
- Apache Storm[7]
- Apache Spark[8]
- SEDA[9]
- h-store[10]
- intra-operator/inter-operator parallelism[11].
主要的关切点由:
- pipelining采用message passing还是shared storage[12][13]?
- intra-stage的多个worker是否需要barrier同步[14][15]?
- pipelining采用command-driven dataflow还是data-driven dataflow[16]?
总之并行处理, 普遍存在于不同的计算层级中(集群, 机器, 多处理器, 多核, 指令流水)普遍采用, 不同的应用场景中(AP, TP, ETL), 不同的workload中. 并行化能够更加有效地利用计算资源, 提升负载, 缩短延迟和提升吞吐.
本文提到的并行处理, 是指在shared memory multiprocessors结构中, 利用多核的并行处理能力, 采用多线程编程, 访问相同地址空间中的in-memory数据结构.
性能(Performance)
性能
可以三个方面来分析性能:
- speedup[1]: 多线程执行相对于单线程执行的加速比, speedup越接近core数越好, 但实际上很难做到.
- CPI(cycles per instruction)[1][17]: 执行一条指令花费的CPU周期数, 越少越好.
- scalability[3][4]: 吞吐随着线程/core数目增加而提升, 越接近线性扩展越好.
性能影响因素有:
- 串行执行: 代码中critical section和contention point数目很多, critical section所辖粒度太大, 采用了heavy-weight synchronization primitives[3][4].
- cache颠簸: CPU分支预测失败, cache miss频繁, 反复invalidate cache等因素导致CPU stall[17].
- 线程数目增大, 负载上升导致线程间的竞争更加激烈, 影响scale-out能力[3][4].
解决方法:
- 减少甚至消除critical section, 减少contention point, 采用轻量级的atomic variable或者memory fence进行inter-thread synchronization[18][19].
- 设计cache friendly算法[20].
正确性(Correctness)
- 程序员能够写出符合预期结果的程序, 能够直观地推知程序的行为.
- 使用轻量级的同步原语和细粒度的设计, 比重量级和粗粒度锁要复杂, 容易出错.
- 编译层面的优化可能是基于对单线程的data/control dependency分析, 会冒进地reorder语句.
- 为了hide store/load latency, 系统可能采用relaxed consistency model. 影响store和load指令program order和write atomicity.
- 处理器的out-of-order schedule, multiple issue和speculative execution会影响program order.
总之, 有诸多因素破坏了program order和write atomicity[1][18].
解决方法
- 线程之间通过原子变量进行同步.
- 插入编程语言或者操作系统提供的{memory, load, store} fence指令以阻止reorder.
总结
程序使用轻量级的同步操作, 设计cache-friendly算法, 减少contention和CPU stall, 尽最大可能提高speedup和降低CPI, 并且具有线性的scale-out能力.
Speedup和Amdahl's Law[1]
Amdahl's Law:
一个程序分为若干fraction: F1, F2, …, Fn; 表示执行时间的占比.
每个fraction的并行度为P1, P2,…,Pn; 表示可并行执行的core数.
speedup为:
speedup = 1 / (F1/P1 + F2/P2 + ... + Fn/Pn)如果串行执行占比为f, 则:
speedup < 1/f, (f ≠ 0)用Amdahl's Law可以估算性能提升.
假如在某in-memory OLTP database, 已经通过micro-benchmark得知:
- 事务平均延迟为1μs;
- 时间戳分配需100ns并且串行执行;
- 其余部分都可以并行执行.
串行执行部分占比为10%, 采用16 socket * 16 core 机器, speedup为:
speedup = 1 / (0.9 / 16*16 + 0.1) = 9.66
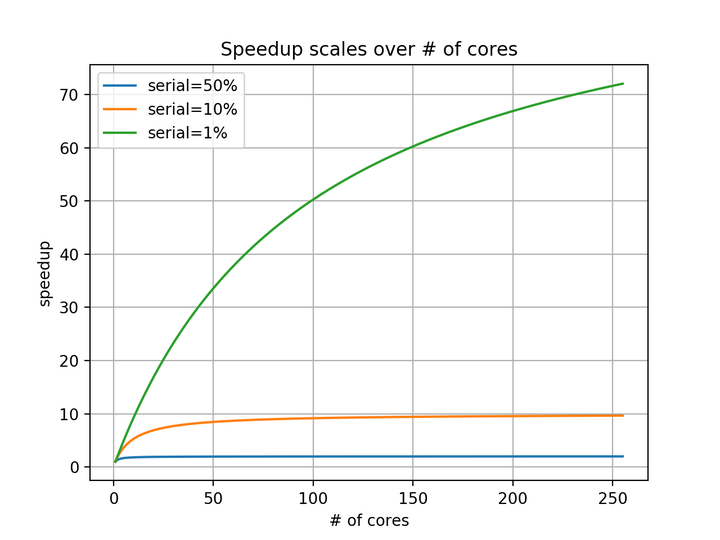
使用256core, 性能最多提升9.66倍.下面两幅图, 可说明
只有在串行执行占比较小的前提下, 增加处理器数量才能显著提高性能(near-linear scalability).
在图"Speedup scales over # of cores"中, 串行占比越大(如10%和50%), near-linear scale的阶段越早结束, 随着core数目上升, speedup迅速收敛(10%, 50%分别对应10, 2). 而占比1%的曲线, 依然强劲增长. 可以得出结论, speedup收敛之后, 增加核数无法显著提高speedup.
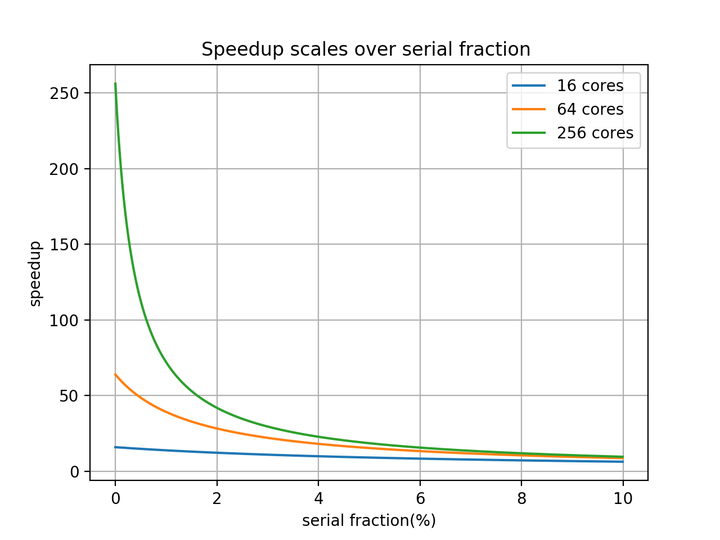
在图"Speedup scales over serial fraction"中, 随着串行占比增加, speedup开始下降. 当串行占比较小时(\<2%), 则增加核数, 能够提升性能; 而串行占比较大时(\>8%), 增加核数没有显著收益.
Cache miss对性能的影响[1]
CPU速度比main memory访问速度快; 而且随着硬件的发展, 速度差异越来越明显. 比如基本CPI为0.2 cycle. 而存取内存需要100 cycle. 两者之间增加多级cache以弥补速度差距. cache造价和功耗较高, 相比于内存, 容量较小. cache失效(未命中)时, 访问memory会造成CPU stall.
a 100% busy CPU could be 95% memory stalled[21].Cache miss分为四类(4C):
- compulsory miss: cache初始时无数据, 需要warmup.
- capacity miss: 容量有限, 装满之后, 加载其他block, 需要evict掉老数据.
- conflict miss: 一个block只能加载到cache的一个set中, set如果满了, 需要evict掉老数据.
- coherence miss: 执行store操作, 废除其他处理器的cache中的copy.
Cache miss对CPI
CPI = BasicCPI + MemoryAccessPerInstruction *(HitTime + MissRate * MissPenalty)
cache的fetch以block为单位,
取指令和存取数的次数平摊到每条指令, 按照MemoryAccessPerInstruction计算.
假设:
BasicCPI = 0.2 cycle,
HitTime = 1 cycle,
MissRate = 3%,
MissPenalty = 100 cycle,
MemoryAccessPerInstruction = 0.3.
则:
CPI = 1.4 cycle, CPI是原来的7倍.
实际上, 如果系统采用L1~L3 cache, 则:
CPI = BasicCPI + MemoryAccessPerInstruction *
(L1_HitTime + L1_MissRate *
(L2_HitTime+ L2_MissRate*
(L3_HitTime + L3_MissRate * MemoryAcessTime)))编译器生产目标代码时, 会对寄存器分配进行优化, 减少从内存中存取中间结果.
分支预测失败, 处理器会排空指令队里, 重新取指. GCC中用__builtin_expect可以提示编译器, 将执行频率高的分支顺序执行.
JIT执行器, 也可根据分支执行频率, 调整机器指令的分支顺序.
文献[20]提到, 在L2 cache颠簸比较严重的情况下, 也会对L1 instruction cache造成显著影响, 需要花费更久的时间从L3或者memory中取指令.
用cache-friendly设计降低cache miss rate
对cache-friendly设计而言, 期望:
- clusering: 数据按访问次序, 聚集在cache line上, 有效利用cache line的大小.
- affinity: core/thread亲附内存的某一地址范围.
- exclusive: core修改私有exclusive copy, 然后安装到共享数据结构中. 修改exclusive copy能够很好地利用latency-hiding技术. 将修改全局数据结构的同步代价平摊到exclusive copy的修改中.
数据如何聚集, 取决于workload. 以数据库的storage model为例:
- NSM(Slotted-page structure)[22]: tuple的字段存在一起, 利tuple materialization, 不利projection.
- DSM(Decomposition Storage Model)[23]: columnar store, 不利tuple materialization, 利projection.
- PAX(Partition Attributes Across)[20]: 混合NSM和DSM
- Fractured Mirrors[24]: 混合NSM和DSM
skiplist/btree[25]
对in-memory key-value系统而言, skiplist和btree比较, 后者对cache更友好. 通常, 在skiplist, 一个key-value pair占据小块内存, 块的大小取决于payload大小和next指针的数目(随机高度). 小块散布, 用指针相连. 搜寻数据时, 指针随机跳转. btree中, 可以将多个key-value pair聚集存储在cache line (64B)中.
hash table
显然采用数组+二次探测的方法对cache不友好. 可以采用bucket方法, 每个bucket由若干块组成, 块的大小采用cache line的整数倍.
affinity[1][4]
工作线程亲附cache或者内存的一段连续的地址区间, 能够减少cache miss. 当使用NUMA或者NUCA结构的机器时, 尤为重要. 工作线程之间尽量彼此独立, 降低contention. 比如h-store实现, 将内存中的数据结构分成若干partition, 每个partition有一个worker认领. 单个partition的事务, 也无需同步. 修改私有的副本, 也能够减少coherence开销.
bw-tree[26]
bw-tree是用cas实现的latch-free B+Tree. 树结点之间的层级关系用logical pointer(i.e. 结点编号)维护, 通过mapping table, 可以将logical pointer转为为physical pointer(i.e. 内存地址). 查询时, 先将root结点的编号转化为内存地址, 然后访问root结点, 挑一个子节点的logical pointer, 如此往复… insert/update/delete不原地修改, 而是创建delte块, 将delta块通过physical pointer指向old page, 然后用cas修改mapping table中的响应的physical pointer值. 树的结点由若干delta块和一个old page组成, 可以采用某种策略对树的结点进行compaction, 将delta 应用于old page中, 采用垃圾回收释放已经废弃的块.
delta块为线程私有, 在安装到mapping table之前, 对其他线程不可见, 因此对delta的写入操作属于cas的前置操作, 可以屏蔽掉. (引文中说可以减少cache invalidation, 未必使然).
TLB
TLB miss对性能影响, 后续再研究.
文献[21]提到, 采用pagesize=4KB, TLB容量是64 entries, 当数据结构的大小超过256KB, TLB miss对性能有明显的影响.
根据[1], TLB也可以采用多级cache.
shared-memory concurrency涉及的面比较广, 要说清楚问题, 可能需要一本书的篇幅. 本文主要的目的, 是给出深入学习的roadmap. 可以把整个学校研究的过程看成是拼图, roadmap能够说明缺失的图块.
Roadmap
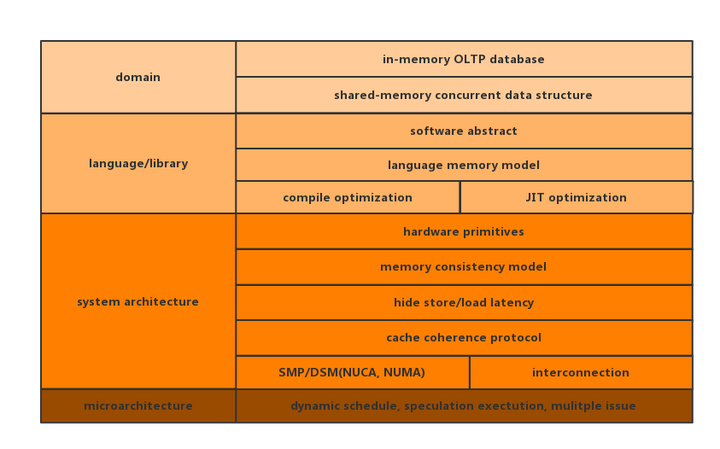
roadmap给出了软件, 系统结构和微结构三个层面的需要考量的问题, 并进一步对每个层面进行了细分.
#1. in-memory OLTP database
面向OLTP的内存数据库是shared memory concurrency的典型应用领域.
TP和AP相比较, 前者一般无需保存过多的历史记录和丰富维度信息, 虽然dataset规模适中, 可全驻内存. 强大的多核计算能力和内存访问速度, 能够满足事务处理的低延迟, 高吞吐的需求. 比如Hekaton[27], Silo[4], TicToc[3]等.
一般地, in-memory database, 也会将系统分为事务处理层和存储层, 两者都会用到轻量级同步方法.
存储层通常采用in-memory concurrent data structure.
#2. shared-memory concurrent data structure
采用并发skiplist, btree或者hash table, 可高效修改,查询key-value.
concurrent data structure采用prefetch, batch write, multiversion, SIMD, version validation和RCU等方法[4].
concurrent数据结构有: MassTree[28], Fractal Tree[29]和Bw-Tree[30] etc.
#3. software abstract
在实现数据结构的时候, 用已被操作系统或编程语言分装过的抽象接口, 比依赖处理器的hardware primitives要方便, 前者便于代码移植, 屏蔽了底层硬件实现细节, 降低了程序员的心智负担.
比如:
- C++ STL:
#include<atomic> - Linux: https://www.kernel.org/doc/Documentation/memory-barriers.txt
- RCU: https://lwn.net/Articles/262464/
#4. language memory model
编程语言层面, 也会定义多线程访问共享变量的行为: reordering, atomic operation, visiable side-effect.
- C++: http://en.cppreference.com/w/cpp/atomic/memory_order
- Go: https://golang.org/ref/mem
- Java: https://docs.oracle.com/javase/specs/jls/se7/html/jls-17.html#jls-17.4
#5. compile optimization/JIT optimization
不管是编译执行还是解释执行, 编译器和解释器可能会对最终生成的机器指令, 进行优化. 改变程序的执行顺序.
- GCC: 可用
asm volatile("" ::: "memory")语句避免重排. - JIT: JIT必然会重排和优化代码, 但是否需要程序员限制过于冒进的优化, 有待进一步学习.
#6. hardware primitives
处理器的指令集提供原子操作和memory fence. 比如x86[31]:
lfence
sfence
mfence
xchg
cmpxchg
lock其他处理器, 请参考[19]
也可搜索Linux源码树:
ag '#define.*mb\b.*asm'
tools/arch/alpha/include/asm/barrier.h
4:#define mb() __asm__ __volatile__("mb": : :"memory")
5:#define rmb() __asm__ __volatile__("mb": : :"memory")
6:#define wmb() __asm__ __volatile__("wmb": : :"memory")
tools/lguest/lguest.c
242:#define wmb() __asm__ __volatile__("" : : : "memory")
243:#define rmb() __asm__ __volatile__("lock; addl $0,0(%%esp)" : : : "memory")
244:#define mb() __asm__ __volatile__("lock; addl $0,0(%%esp)" : : : "memory")
tools/arch/powerpc/include/asm/barrier.h
25:#define mb() __asm__ __volatile__ ("sync" : : : "memory")
26:#define rmb() __asm__ __volatile__ ("sync" : : : "memory")
27:#define wmb() __asm__ __volatile__ ("sync" : : : "memory")
tools/arch/tile/include/asm/barrier.h
11:#define mb() asm volatile ("mf" ::: "memory")
tools/arch/x86/include/asm/barrier.h
19:#define mb() asm volatile("lock; addl $0,0(%%esp)" ::: "memory")
20:#define rmb() asm volatile("lock; addl $0,0(%%esp)" ::: "memory")
21:#define wmb() asm volatile("lock; addl $0,0(%%esp)" ::: "memory")
23:#define mb() asm volatile("mfence":::"memory")
24:#define rmb() asm volatile("lfence":::"memory")
25:#define wmb() asm volatile("sfence" ::: "memory")
tools/arch/mips/include/asm/barrier.h
10:#define mb() asm volatile( \
tools/arch/arm64/include/asm/barrier.h
12:#define mb() asm volatile("dmb ish" ::: "memory")
13:#define wmb() asm volatile("dmb ishst" ::: "memory")
14:#define rmb() asm volatile("dmb ishld" ::: "memory")
tools/arch/sh/include/asm/barrier.h
25:#define mb() __asm__ __volatile__ ("synco": : :"memory")
tools/arch/s390/include/asm/barrier.h
25:#define mb() do { asm volatile(__ASM_BARRIER : : : "memory"); } while (0)
tools/arch/xtensa/include/asm/barrier.h
14:#define mb() ({ __asm__ __volatile__("memw" : : : "memory"); })
tools/arch/sparc/include/asm/barrier_64.h
39:#define rmb() __asm__ __volatile__("":::"memory")
40:#define wmb() __asm__ __volatile__("":::"memory")
tools/testing/selftests/powerpc/dscr/dscr.h
39:#define rmb() asm volatile("lwsync":::"memory")
40:#define wmb() asm volatile("lwsync":::"memory")
tools/testing/selftests/powerpc/include/reg.h
19:#define mb() asm volatile("sync" : : : "memory");
arch/alpha/include/asm/barrier.h
6:#define mb() __asm__ __volatile__("mb": : :"memory")
7:#define rmb() __asm__ __volatile__("mb": : :"memory")
8:#define wmb() __asm__ __volatile__("wmb": : :"memory")
arch/frv/include/asm/barrier.h
17:#define mb() asm volatile ("membar" : : :"memory")
18:#define rmb() asm volatile ("membar" : : :"memory")
19:#define wmb() asm volatile ("membar" : : :"memory")
arch/frv/include/asm/io.h
43://#define __iormb() asm volatile("membar")
44://#define __iowmb() asm volatile("membar")
arch/powerpc/include/asm/barrier.h
33:#define mb() __asm__ __volatile__ ("sync" : : : "memory")
34:#define rmb() __asm__ __volatile__ ("sync" : : : "memory")
35:#define wmb() __asm__ __volatile__ ("sync" : : : "memory")
45:#define dma_wmb() __asm__ __volatile__ (stringify_in_c(SMPWMB) : : :"memory")
51:#define __smp_wmb() __asm__ __volatile__ (stringify_in_c(SMPWMB) : : :"memory")
arch/arm/include/asm/barrier.h
18:#define dmb(option) __asm__ __volatile__ ("dmb " #option : : : "memory")
24:#define dmb(x) __asm__ __volatile__ ("mcr p15, 0, %0, c7, c10, 5" \
31:#define dmb(x) __asm__ __volatile__ ("" : : : "memory")
36:#define dmb(x) __asm__ __volatile__ ("" : : : "memory")
arch/arc/include/asm/barrier.h
29:#define mb() asm volatile("dmb 3\n" : : : "memory")
30:#define rmb() asm volatile("dmb 1\n" : : : "memory")
31:#define wmb() asm volatile("dmb 2\n" : : : "memory")
41:#define mb() asm volatile("sync\n" : : : "memory")
47:#define mb() asm volatile (".word %0" : : "i"(CTOP_INST_SCHD_RW) : "memory")
48:#define rmb() asm volatile (".word %0" : : "i"(CTOP_INST_SCHD_RD) : "memory")
arch/x86/um/asm/barrier.h
26:#define mb() asm volatile("mfence" : : : "memory")
27:#define rmb() asm volatile("lfence" : : : "memory")
28:#define wmb() asm volatile("sfence" : : : "memory")
arch/x86/include/asm/barrier.h
14:#define mb() asm volatile(ALTERNATIVE("lock; addl $0,0(%%esp)", "mfence", \
16:#define rmb() asm volatile(ALTERNATIVE("lock; addl $0,0(%%esp)", "lfence", \
18:#define wmb() asm volatile(ALTERNATIVE("lock; addl $0,0(%%esp)", "sfence", \
21:#define mb() asm volatile("mfence":::"memory")
22:#define rmb() asm volatile("lfence":::"memory")
23:#define wmb() asm volatile("sfence" ::: "memory")
arch/sh/include/asm/barrier.h
27:#define mb() __asm__ __volatile__ ("synco": : :"memory")
33:#define __smp_mb() do { int tmp = 0; __asm__ __volatile__ ("cas.l %0,%0,@%1" : "+r"(tmp) : "z"(&tmp) : "memory", "t"); } while(0)
arch/mips/include/asm/barrier.h
206:#define smp_llsc_mb() __asm__ __volatile__(__WEAK_LLSC_MB : : :"memory")
arch/arm64/include/asm/atomic_ll_sc.h
58:#define ATOMIC_OP_RETURN(name, mb, acq, rel, cl, op, asm_op) \
80:#define ATOMIC_FETCH_OP(name, mb, acq, rel, cl, op, asm_op) \
152:#define ATOMIC64_OP_RETURN(name, mb, acq, rel, cl, op, asm_op) \
174:#define ATOMIC64_FETCH_OP(name, mb, acq, rel, cl, op, asm_op) \
arch/arm64/include/asm/barrier.h
31:#define dmb(opt) asm volatile("dmb " #opt : : : "memory")
arch/arm64/include/asm/atomic_lse.h
49:#define ATOMIC_FETCH_OP(name, mb, op, asm_op, cl...) \
246:#define ATOMIC64_FETCH_OP(name, mb, op, asm_op, cl...) \
arch/xtensa/include/asm/barrier.h
12:#define mb() ({ __asm__ __volatile__("memw" : : : "memory"); })
arch/unicore32/include/asm/barrier.h
15:#define dmb() __asm__ __volatile__ ("" : : : "memory")
arch/s390/include/asm/barrier.h
23:#define mb() do { asm volatile(__ASM_BARRIER : : : "memory"); } while (0)
arch/sparc/include/asm/barrier_64.h
37:#define rmb() __asm__ __volatile__("":::"memory")
38:#define wmb() __asm__ __volatile__("":::"memory")# 7.memory consistency model[1][5][19]
多个processor访问多个shared memory location必须遵守的规则.
处理器访问私有memory location (local scoped变量和TLS), 编译器和处理器优化能够保持data dependency/control dependency[1].
多处理器在保证control/data dependency的前提下, 容许单个处理器对不同memory location的操作进行重排, 可能产生不一致的结果.
例如: 下面代码中, 直观上(x,y)可取(1,1), (0, 1)和(1, 0); 但也可能取到(0, 0).
a = 0;
b = 0;
x = 0;
y = 0;
processor1:
a = 1;
x = b;
processor2:
b = 1;
y = a;
处理器其实难以区分, 存取指令所谓访问的memory location是私有还是共享. 对于uniprocessor, 重排是可接受的; 对于multiprocessor, 重排会出现非预期的结果.
在谈到memory consistency model时, SC(sequential consistency)[32][33][34]首先会被提及. SC有很多等价的表述方法.
SC除了单个处理器保证control/data dependency之外, 还需要添加两个条件:
- program order requirement: 单处理器访问不同memory location, 需要保证program order.
- write atomicity requirement: 多处理器访问相同memory location, 要等待outstanding write操作完成后进行.
后面的所有讨论, 都假定cache采用write-back方式.
当多个处理器在私有cache中有数据的shared copy时, 其中一个处理器修改数据, 其他处理器如果不等待该处理器完成而读取stale的结果, 会产生不一致的结果.
SC和Linearizability[34]不同的时, 操作不必在invocation和reponse之间生效. 操作生效时间点可以延迟到reponse之后, 但依然需要满足:
- 操作是逐个生效的.
- 单个处理器的操作是按照program order的顺序生效的.
这就说明, 可以采用一些hide store/load latency的技术, 提前返回, 插入一些修改私有数据的存取指令或者非访存的指令执行.
SC是程序正确性的保证, 但是究竟哪些存取指令需要遵从SC呢? 这是一个值得商榷的问题.
其实, 只要保证存取共享的memory location的SC即可.
如果把存取共享的memory location的操作分为两类: data operation和synchronization operation. 假如采用的synchronization operation为smp_mb, smp_wmb和smp_rmb.
- smp_wmb之前代码不能挪到smp_wmb之后执行.
- smp_rmb之后代码不能挪到smp_wmb之后执行.
- smp_mb相当于smp_wmb+smp_rmb的效果.
显然单处理器上的synchronization operation的执行按照program order, data operation相对于synchronization operation的执行顺序也按照program order, 但是相邻的data operation操作可以reorder, 而且smp_wmb之后的代码也容许挪到smp_wmb之前, smp_rmb之前的代码, 也可以挪到smp_rmb之后.
这样一来, 并非所有存取指令需遵从SC. 可以放宽program order requirement和write atomicity requirement. relaxed memory model就是指这两个条件的放宽[5].
结论
uniprocessor的指令调度保证data/control dependency,
multiprocessor通过synchronization保证先后次序,
uniprocessor的data operation和synchronization operation要保证相对的program order,
processor提供atomic operation和memory fence用于synchronization,
programmer决定atomic operation和memory fence插入的位置.
容许相邻的data operation在保证data/control dependency的前提下, 重排.
比如[5]:
TSO (Total Store Ordering): 容许W-R重排.
PSO (Partial Store Ordering): 容许W-R, W-W重排.
WO (Weak Ordering): 容许W-R, W-W, R-W, R-R重排.
#8.hide store/load latency[1][19]
接着前文提及SC容许processor存取操作在生效之前返回, 存取指令可以相互overlapping.
Time-shared common bus
multiprocessor和私有cache之间通过shared bus连接, uniprocessor的存取操作需要分时互斥地持有总线, 直到操作完成. 此方式简单直观, 能够很好地保证write atomicity, 却性能不好.
写操作:
processor: P0,P1和P2
1. P0申请并获得总线
2. P0修改cache line
3. P0广播invalidate msg给P1和P2
4. P1和P2收到invalidate msg后, 标记相应的cache line为invalid, 然后恢复ack.
5. P0收到来自P1和P2的invalidate ack.
6. P0释放总线.读操作:
processor: P0,P1和P2
1. P1因为总线占用,而持续等待, 直到总线空闲, 仲裁逻辑授予P1总线的使用权.
2. P1发送地址, 读cache line.
3. 如果cache line被标记为invalid或者read miss, 则从其他下一级cache或其他处理器的私有cache获取copy.
4. P1从加载完up-to-date copy到cache line中获取地址指定的数据.
5. P1释放总线.总线互斥访问的方法保证write atomicity, 会引入CPU stall.
引入store buffer(也有文献提到write buffer)
store buffer相当于queue, 用于保存processor的store操作.
processor执行store fence指令, 标记store buffer中的现有的store操作.
可以采用计数器, 或者直观上想象, 执行store fence指令, 就是在store buffer的队尾插入一个barrier标记.
store buffer中, 只有当store fence的前置的操作flush到cache之后, 后置的操作才能flush.
processor只有收到其他processor的关于store操作invalidate ack之后, 才能将该store操作flush到cache中.
所以:
- processor执行store fence指令, 向store buffer插入fence标记.
- processor执行store指令, 如果目标cache line不处于Modified/Exclusive状态或者store buffer中有fence标记, 则将store操作放入store buffer中.
- 否则, 说明目标cache为processor所独享并且无必须前置完成的store操作, 则直接修改cache.
store fence并不是意味着清空store buffer, 而是保证fence标记前后的store操作的生效顺序. 生效是指:
- 其他processor的cache已经感知到store操作, 并且设置cache line为invalid;
- store指令的发起者将操作flush到cache中.
引入invalidate queue
收到invalidate msg的, processor将msg放入invalidate queue中, 然后及时向store操作的发起者发送ack.
processor可以后续处理invalidate msg, 将cache line置为invalid.
同样地, processor可执行load fence在invalidate queue中插入fence标记. 当processor发起load操作时, 如果有前置的invalidate msg, 则stall直到前置的cache line被置为invalid.
处理器会通过memory fence指令, 兼具store fence和load fence的效果.
#9. cache coherence protocol
coherence和consistency有什么区别呢?
[1]p.411: Coherence defines the behavior of reads and writes to the same memory location, while consistency defines the behavior of reads and writes with respect to accesses to other memory locations.coherence是指multiprocessor存取同一个memory location, 所有processor感知到相同的访问次序.
所修改的目标copy在以shared状态加载在其他处理器中, 需要发送invalidate msg让其失效. 其他处理器后续读该copy时, 发现状态为invalid, 能够触发read miss, 重新fetch数据.
consistency是指multiprocessor把用于synchronization operation的memory location作为data operation生效次序的参考.
如果两个processor访问的memory location毫无交集, 则无需同步; 即便有共享的memory location, 不关心存取操作发生的次序是否被所有processor观察到相同次序, 也无需同步.
比如: 不同processor中成对出现的release-acquire. release修饰的store操作的结果, 被acquire修饰的load操作读到, 则前者必然先于后者发生. 并且: (→表示happen before)
release前置操作 → release操作;
acquire操作 → acquire后置操作;
release操作 → acquire操作;
必然:
release前置操作 → acquire操作
cache coherence protocol协议分为三类:
- invalidate-based protocol(snooping protocol)
- directory-based protocol
- update-based protocol
只有处理器的私有cache, 如L1和L2, 会拥有同一个block的各自的copy, 需保持一致. 共享cache, 如L3, 则无需考虑.
下文提到的coherence协议, 均采用write-back策略.
invalidate-based protocol
前文已多次提及.
简言之: 发起store操作处理器, 向其他所有处理器广播invalidation msg, 等待其他处理器设置copy为invalid状态并回复ack msg. 所有的处理器除了需要探听(snoop名字的由来) invalidate msg, 还需要探听read/write miss msg, 当处理器探听到cache miss消息后, 如果处理器自身拥有目标地址的copy已经处于Modified状态; 需要write-back该copy到共享存储器中, 或者直接forward该copy给cache miss的触发者.
invalidate-based protocol有很多变种, 根据cache维护的状态命名. 文献[19]提到, cache实现比模型更复杂, 可能会维护数十状态.
1. MSI (Modified, Shared, Invalid)[1]
除了Modified状态外, store操作的请求者广播invalidate msg.
requestor遇到cache miss, 从下级共享存储器传输数据.
Modified状态侦听到cache miss, 要write-back到下级共享存储器.2. MESI (Modified, Exclusive, Shared, Invalid)[1]
Exclusive状态是MSI中Shared状态的一种.
当processor是唯一sharer时, 则cache line处于Exclusive状态.
修改Exclusive状态不必广播invalidate msg.
Exclusive状态的cache line被修改后, 转化为Modified状态.
cache miss的处理同MSI.3. MESIF (Modified, Exclusive, Shared, Invalid, Forward)[1][35]
广播invadidate msg的处理同MESIF.
Forward是一种特殊的Shared状态, 最多指定一个sharer为Forward状态.
如果侦听到cache miss, 则Forward状态的processor采用cache-to-cache传输数据.
cache-to-cache传输, 比从下级共享存储器传输数据要快.4. MOESI (Modified, Owned, Exclusive, Shared, Invalid)[1][35]
Owned是特殊的Modified状态, 表示下级共享存储器中的数据已经out-of-date.
广播invalidate msg的处理同MESI.
如果侦探到cache miss, 则Owned状态的processor采用cache-to-cache传输数据.显然, 减少snoop代价, 采用cache-to-cache transfer可以改善性能.
snooping协议的主要问题是要向所有的处理器广播invalidate msg, 并且所有的处理器需要侦听cache miss/invalidate msg, 需要占用过多interconnection network的带宽, 所以scalability较差. 相较于directory-based protocol, 支持的处理器数目较少.
directory-based protocol[1]
directory协议也需要在store的时候, 将其他shared copy标记为invalid. 但只需要将invalidate msg发送给shared copy即可; 因此, interconnection的带宽竞争不如invalidate激烈.
将下级共享存储器(比如L3 cache)的block在状态信息保存directory中, directory entry可看做bitvector, 每个bit对应一个处理器, 表示是否位于处理器的私有cache中. 显然, 根据bitvector的信息, 结合cache line的状态信息, 可以判断是否需要发送invalidate msg, 以及向谁点对点的发送.
采用centralized directory, 随着处理器的数目上升, 多处理器竞争会更加激烈. 因此, 采用distributed directory.
所以, 为了支持更多数目的处理器, 往往采用NUMA或者NUCA的系统结构. 将main memory或者L3 cache划分给多处理器, 每个处理器本地访问速度快于异地访问. 存储器分区的对应的directory entry也有同一个处理器认领.
update-based protocol
实现思路类似RSM, overhead比较高, 不再赘述, 可参考文献[5]
#10.SMP/DSM和interconnection network [1]
处理器, 存储模块之间传递消息的媒介, 称为interconnection network.
主要类型有:
- time-shared common bus
- multiport memory
- crossbar switch
- multistage switch
- hypercube
point-to-point(除time-shared common bus)的方式, 能够提供多个消息通路, 在设计上比bus复杂, 但可获得更高的带宽.
处理器, 多级cache和main memory可以组合方式有:
- SMP(Symmetric Multiprocessors): centralized organization of main memory/outermost cache.
- NUCA(Nonuniform Cache Access): centralized main memory, distributed outermost cache.
- NUMA(Nonuniform Memory Access): distributed main memory.
SMP和NUCA, NUMA都采用shared memory, i.e. 所有的处理器可以访问整个地址空间.
这里的中心化/分布式的区别不在于memory的bank数量, 而是指将memory划片后, 分给处理器. 处理器访问自己本地分片, 只会经过自己cache; 访问异地分片, 需要请求别的处理器forward. 所以, 访问本地数据的延迟比异地数据要低. 上层应用可以利于处理器和本地分片的亲和性, 让处理器尽可能访问本地数据.
#11. Instruction-Level Parallelism[1]
ILP涉及处理器的设计和实现, 从程序员的角度理解:
- 指令通过pipeline并行叠加执行.
- 能够保证data/control dependency.
- 必要时, 程序员要用synchronization operation(atomic, fence)限制指令的out-of-order调度.
文献[1]对ILP做了非常详尽的分析.
参考文献
[1] J. L. Hennessy and D. A. Patterson, “Computer architecture: a quantitative approach,” 2011.
[2] https://ark.intel.com/products/96900/Intel-Xeon-Processor-E7-8894-v4-60M-Cache-2_40-GHz
[3] X. Yu, A. Pavlo, D. S. 0003, and S. Devadas, “TicToc - Time Traveling Optimistic Concurrency Control.,” SIGMOD Conference, pp. 1629–1642, 2016.
[4] S. Tu, W. Zheng, E. Kohler, B. Liskov, and S. Madden, “Speedy transactions in multicore in-memory databases.,” SOSP, pp. 18–32, 2013.
[5] S. V. Adve and K. Gharachorloo, “Shared memory consistency models: A tutorial,” computer, vol. 29, no. 12, pp. 66–76, 1996.
[6] J. Dean and S. Ghemawat, “MapReduce: simplified data processing on large clusters,” Communications of the ACM, vol. 51, no. 1, pp. 107–113, 2008.
[7] http://storm.apache.org/releases/2.0.0-SNAPSHOT/index.html
[8] M. Zaharia, R. S. Xin, P. Wendell, T. Das, M. Armbrust, A. Dave, X. Meng, J. Rosen, S. Venkataraman, and M. J. Franklin, “Apache spark: a unified engine for big data processing,” Communications of the ACM, vol. 59, no. 11, pp. 56–65, 2016.
[9] M. Welsh, D. Culler, and E. Brewer, “SEDA: an architecture for well-conditioned, scalable internet services,” vol. 35, no. 5, pp. 230–243, 2001.
[10] M. Stonebraker, S. Madden, D. J. Abadi, S. Harizopoulos, N. Hachem, and P. Helland, The end of an architectural era: (it's time for a complete rewrite). VLDB Endowment, 2007, pp. 1150–1160.
[11] http://15721.courses.cs.cmu.edu/spring2016/slides/10.pdf
[12] D. Peng, F. D. OSDI, 2010, “Large-scale Incremental Processing Using Distributed Transactions and Notifications.,” http://usenix.org.
[13] O. Shacham, F. Perez-Sorrosal, E. B. P. O. T. 15th, 2017, “Omid, reloaded: scalable and highly-available transaction processing,” http://usenix.org.
[14] https://en.wikipedia.org/wiki/Bulksynchronousparallel
[15] G. Malewicz, M. H. Austern, A. J. Bik, J. C. Dehnert, I. Horn, N. Leiser, and G. Czajkowski, “Pregel: a system for large-scale graph processing,” pp. 135–146, 2010.
[16] G. Graefe, Volcano: An Extensible and Parallel Query Evaluation System. 1989.
[17] B. Gregg, “Systems performance: enterprise and the cloud,” 2013.
[18] S. V. Adve and K. Gharachorloo, “Shared memory consistency models: A tutorial,” computer, vol. 29, no. 12, pp. 66–76, 1996.
[19] P. E. McKenney, “Memory barriers: a hardware view for software hackers,” Linux Technology Center, IBM Beaverton, 2010.
[20] A. Ailamaki, D. J. DeWitt, M. D. Hill, M. S. VLDB, 2001, “Weaving Relations for Cache Performance.,” http://vldb.org.
[21] P. A. Boncz, M. L. Kersten, and S. Manegold, “Breaking the memory wall in MonetDB,” Communications of the ACM, vol. 51, no. 12, pp. 77–85, 2008.
[22] A. Silberschatz, H. F. Korth, and S. Sudarshan, Database System Concepts. McGraw-Hill Education, 2011.
[23] D. J. Abadi, S. R. Madden, N. H. P. O. T. 2. ACM, 2008, “Column-stores vs. row-stores: how different are they really?,” http://dl.acm.org.
[24] R. Ramamurthy, D. J. DeWitt, Q. S. T. V. Journal, 2003, “A case for fractured mirrors,” Springer.
[25] http://15721.courses.cs.cmu.edu/spring2016/slides/06.pdf
[26] http://15721.courses.cs.cmu.edu/spring2016/slides/07.pdf
[27] P.-Å. Larson, S. Blanas, C. Diaconu, C. Freedman, J. M. Patel, and M. Zwilling, “High-Performance Concurrency Control Mechanisms for Main-Memory Databases,” http://arXiv.org, vol. cs.DB. 31-Dec-2011.
[28] Y. Mao, E. Kohler, and R. T. Morris, “Cache craftiness for fast multicore key-value storage,” EuroSys '12, pp. 183–196, 2012.
[29] M. A. Bender, M. Farach-Colton, J. T. Fineman, Y. R. Fogel, B. C. Kuszmaul, and J. Nelson, “Cache-oblivious streaming B-trees,” pp. 81–92, 2007.
[30] J. J. Levandoski, D. B. Lomet, and S. Sengupta, “The Bw-Tree: A B-tree for new hardware platforms,” pp. 302–313, 2013.
[31] Intel Corporation, “Intel® 64 and IA-32 Architectures Software Developer’s Manual Volume 2 (2A, 2B, 2C & 2D): Instruction Set Reference, A-Z,” pp. 1–2226, Mar. 2018.
[32] H. Attiya, J. W. A. T. O. C. S. TOCS, 1994, “Sequential consistency versus linearizability,” http://dl.acm.org.
[33] L. L. I. T. O. computers1979, “How to make a multiprocessor computer that correctly executes multiprocess progranm,” http://ieeexplore.ieee.org.
[34] M. P. Herlihy, J. W. A. T. O. P. Languages, 1990, “Linearizability: A correctness condition for concurrent objects,” http://dl.acm.org.